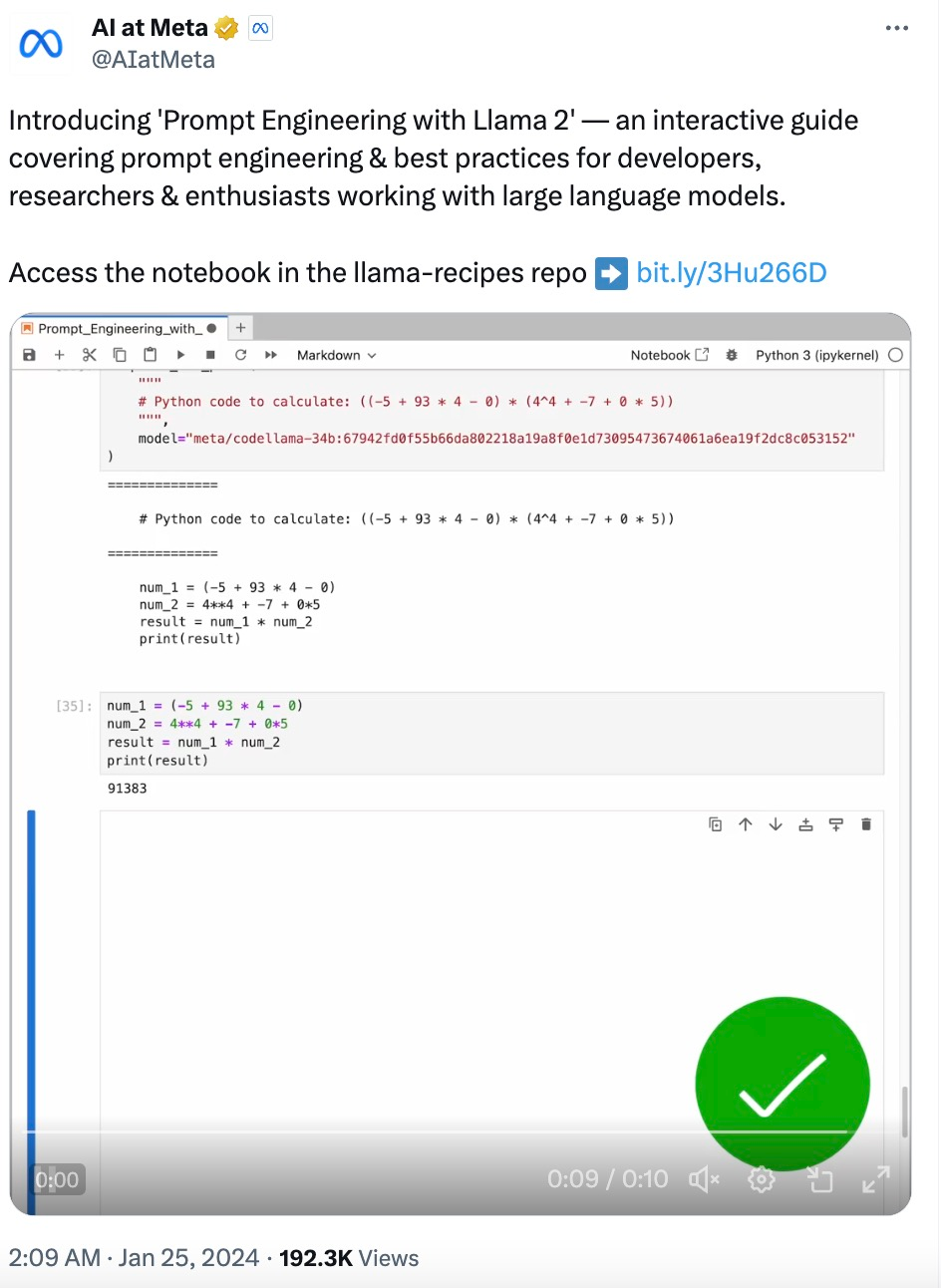
Meta官方的Prompt工程指南:Llama 2这样用更高效
Meta官方的Prompt工程指南:Llama 2这样用更高效随着大型语言模型(LLM)技术日渐成熟,提示工程(Prompt Engineering)变得越来越重要。一些研究机构发布了 LLM 提示工程指南,包括微软、OpenAI 等等。
来自主题: AI技术研报
7733 点击 2024-01-29 12:36
 搜索
搜索
随着大型语言模型(LLM)技术日渐成熟,提示工程(Prompt Engineering)变得越来越重要。一些研究机构发布了 LLM 提示工程指南,包括微软、OpenAI 等等。

IPA 已经成了现代智能手机不可或缺的标配,近期的一篇综述论文更是认为「个人 LLM 智能体会成为 AI 时代个人计算的主要软件范式」。

近日,CMU Catalyst 团队推出了一篇关于高效 LLM 推理的综述,覆盖了 300 余篇相关论文,从 MLSys 的研究视角介绍了算法创新和系统优化两个方面的相关进展。
进入现今的大模型 (LLM) 时代,又有研究者发现了左右互搏的精妙用法!近日,加利福尼亚大学洛杉矶分校的顾全全团队提出了一种新方法 SPIN(Self-Play Fine-Tuning),可不使用额外微调数据,仅靠自我博弈就能大幅提升 LLM 的能力。

近日,美团、浙大等推出了能够在移动端部署的多模态大模型,包含了 LLM 基座训练、SFT、VLM 全流程。也许不久的将来,每个人都能方便、快捷、低成本的拥有属于自己的大模型。

作者重点关注了基于 Transformer 的 LLM 模型体系结构在从预训练到推理的所有阶段中优化长上下文能力的进展。
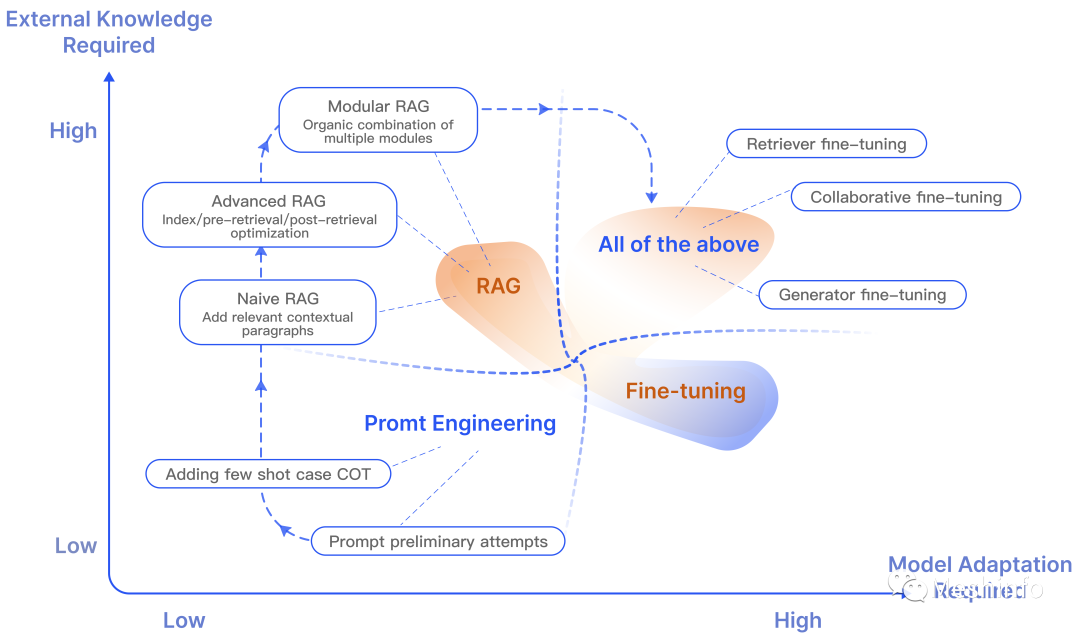
RAG没有想象中那么容易。相信这也是你会看到这篇文章的原因。

大语言模型(LLM)被越来越多应用于各种领域。然而,它们的文本生成过程既昂贵又缓慢。这种低效率归因于自回归解码的运算规则:每个词(token)的生成都需要进行一次前向传播,需要访问数十亿至数千亿参数的 LLM。这导致传统自回归解码的速度较慢。

随着大型语言模型(LLM)的发展,从业者面临更多挑战。如何避免 LLM 产生有害回复?如何快速删除训练数据中的版权保护内容?如何减少 LLM 幻觉(hallucinations,即错误事实)? 如何在数据政策更改后快速迭代 LLM?这些问题在人工智能法律和道德的合规要求日益成熟的大趋势下,对于 LLM 的安全可信部署至关重要。

大模型的效果好不好,有时候对齐调优很关键。但近来很多研究开始探索无微调的方法,艾伦人工智能研究所和华盛顿大学的研究者用「免调优」对齐新方法超越了使用监督调优(SFT)和人类反馈强化学习(RLHF)的 LLM 性能。